
近一年来,AI医疗领域正进入一个明显不同于以往的新阶段。国内外大型科技公司、医药企业和产业资本正通过多种方式进入该领域。一个清晰的共识正在形成:医疗正成为少数真正需要、也能够检验大模型能力上限的核心场景之一。然而,现实问题同样突出。尽管应用数量快速增长,但受限于能力,真正能进入医疗核心流程的AI依然有限。当前主流医疗大模型大多仍建立在静态问答或角色扮演范式之上,模型被要求给出看似合理、语气专业的回答,却并不真正理解医疗决策是如何发生的。这类模型往往难以主动发现信息缺口,无法构建完整的医学推理路径,也缺乏对医疗幻觉的有效约束。行业真正需要的,并非更像医生的回答,而是更接近医疗决策过程本身的模型能力。
百川智能给出的解法正是从这一点切入。其新一代医疗增强大语言模型Baichuan-M3,没有继续强化问答或对话表现,而是将训练目标直接对准医疗决策过程本身。模型被训练为能够主动收集关键信息、构建医学推理路径,并在推理过程中持续抑制幻觉。这意味着模型第一次被系统性地当作决策参与者,而非回答生成器。这种能力定义的变化,直接提升了模型在真实医疗场景中的可用性与可靠性。
在多项医疗评测中,Baichuan-M3展现出超越当前国际主流模型的表现。其优势并不体现在表达更自然,而在于判断更稳定、推理更完整、风险更可控。具体而言,其领先主要体现在三个关键评测维度上。
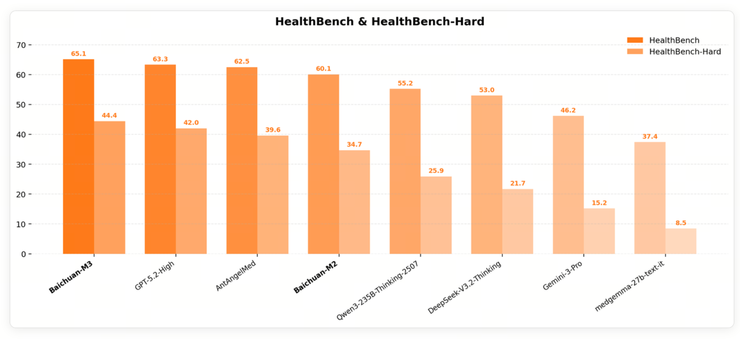
首先,在由OpenAI发布的HealthBench医疗健康评测基准及其高难度子集HealthBench-Hard的测试中,Baichuan-M3表现出了明显的代际提升,刷新了该基准的最好成绩。这说明在更复杂、更接近真实使用环境的医疗场景中,模型的稳定性和一致性已明显提高。
其次,在医疗幻觉控制方面,Baichuan-M3重点前移至模型本身,旨在减少模型仅凭内部知识生成时出现幻觉。通过更严格的评估方式,模型在无工具场景下的事实准确性已超过国际主流模型,意味着模型在信息不充分时更倾向于收敛判断、降低风险。
第三,在端到端的严肃问诊能力上,百川提出了“严肃问诊范式”与“SCAN原则”,将临床问诊中高度依赖经验的思维过程系统性地“白盒化”。基于此构建的SCAN-bench评测体系,完整模拟医生从接诊到确诊的全过程。在该评测中,Baichuan-M3在临床问诊、实验室检查建议和最终诊断三个核心环节均取得最高准确率,尤其在临床问诊阶段得分显著高于其他模型及人类基线水平。
整体来看,Baichuan-M3在三个维度上的领先并非零散成绩,而是同一套设计思路在不同评测体系中的集中体现。当模型被训练为真正理解医疗决策是如何一步步发生时,它在真实医疗场景中的长期使用价值才真正开始成立。百川的路径或许代表着AI医疗正在发生的一次重要转向:行业关注点正从模型能否回答医学问题,转向模型是否能被信任地嵌入医疗系统。

