
2026年最新AI离线工具大全:无需联网即可运行的高效人工智能软件与模型完整盘点
分类:AI动态 浏览量:468
为什么需要离线AI工具
你有没有遇到过这种尴尬?客户现场演示PPT,公司内网突然抽风,云API返回一张404;或者出差在飞机上,老板让你「马上把这份英文合同摘要出来」,却只能对着空白屏幕发呆。我把这类场景统称为「断网焦虑症」——不是没网,而是不敢把命脉押在网线上。
离线AI像给电脑装了颗「第二心脏」。它跳得慢点,却稳得多。更重要的是,数据不出门,合规部门不再半夜敲你门;带宽不占用,月底不再看着流量账单心疼;延迟低到毫秒级,做实时字幕也不会出现「说了三句,第一句才缓缓飘出来」的喜剧效果。
数据隐私与合规要求
我曾在一家医疗初创做顾问,他们想把病历做脱敏翻译,结果法务一句「患者数据离院即违规」就把云方案枪毙。最后我们用7B的本地中文模型+医学词表,在院内服务器跑通翻译,审计老师现场拔网线测试,才在报告上签字。隐私不是口号,是「物理断网」那一刻的安心。
网络受限场景应用
矿山、远洋船舶、边疆基站,这些地方不是信号差,而是根本没有信号。我把Jetson Orin装进防爆壳,塞在矿车驾驶室里,跑YOLOv9做传送带异物检测;工人师傅说,这比让他们背「十不准」条例直观多了,毕竟屏幕实时框出煤里的雷管,谁都能看懂。
降低延迟与节省带宽
云API再快,也跨不过「地球周长」这条硬杠杠。北京调美国机房,光在光纤里就要跑120ms,更别提排队、鉴权、序列化这些杂七杂八的损耗。本地模型?我的笔记本RTX 4080跑SDXL Turbo,512×512图只要0.8秒,省下的不只是时间,还有每次4MB的上传流量——别小看,做批处理时移动硬盘里的10万张图就能省出几百块流量费。
2026年离线AI工具选型标准
选离线工具就像挑越野车:光看马力不够,得问能不能加92号油、备胎好不好找、后排能不能放自行车。我把过去三年踩过的坑总结成「三问三看」:问硬件、问体积、问协议;看更新、看精度、看散热。下面拆开聊。
硬件兼容性与最低配置
Ollama官方说8G内存能跑7B模型,实际上Windows后台再挂个微信,就频频OOM。我的底线是:Windows留4G、Linux留2G,再给模型8G,所以16G内存起步;显卡显存更直白,7B int4量化要6G,14B就得12G,想跑30B?乖乖上24G。别信「CPU也能跑」的鬼话,能跑和跑得动是两码事。
模型大小与存储占用
我有一块2TB的移动硬盘,被同事笑称「AI弹药库」。实际上一个SDXL Turbo完整权重就要6.94GB,再加上LoRA、VAE、ControlNet,轻轻松松破20G。语言模型更离谱,Qwen-14B-int4压缩后也要8G,再算上知识库、历史对话缓存,100G硬盘转眼就红。所以我现在给项目做预算时,先把「硬盘单价」写进报价单,客户反而觉得专业。
开源协议与商业授权
Meta的Llama 2社区版允许商用,但月活大于7亿就要单独谈授权;谷歌Gemma则干脆禁止托管服务。换句话说,你今天用Gemma给客户做内网问答,明天客户把系统卖给大厂,你就踩雷了。我的做法是:合同里写死「基于MIT/BSD模型开发」,把责任推回给客户法务,谁爱头疼谁头疼。
离线更新与版本管理
离线≠万年不更新。我做过的政府项目要求「季度补丁包」:把增量权重、新词表、漏洞修复打包成iso,走保密局光盘流程。听起来麻烦,却比「半夜偷偷连外网拉模型」安全得多。工具链我推荐Ollama的`.mod`文件+Git LFS,版本号写进文件名,回滚只要一行命令,运维老哥夸我「比装Windows驱动还简单」。
离线自然语言处理工具
如果只能留一个离线AI,我会毫不犹豫选大语言模型。它像万能插座,插上翻译、摘要、问答、Json提取各种插头,都能亮。下面这几款是我硬盘常驻嘉宾,各有千秋。
LLM离线推理框架:Llama.cpp、Ollama、KoboldCPP
Llama.cpp是祖师爷,纯C++无依赖,连Windows 7老机器都能跑;Ollama像「傻瓜相机」,一条命令拉模型,自动帮你调线程、吃满AVX512;KoboldCPP则带GUI,写小说的人最爱,能记忆人物关系,还能插卡出图。实际测下来,同一块13700K,Ollama比Llama.cpp快8%,KoboldCPP慢5%但省得自己写前端,看你爱折腾还是爱偷懒。
中文优化模型:ChatGLM3-6B、Baichuan2-7B、Qwen-14B
ChatGLM3-6B像「南方小土豆」,参数小、脾气好,4bit量化后3.5G,笔记本就能飞;Baichuan2-7B则像「西北大汉」,知识截止2024年,写公文、编法规一把好手;Qwen-14B是「全科状元」,代码、数学、中英混排都稳,但显存直接翻倍。我的组合是:6B放前台做聊天,14B扔后台做批处理,夜里让它慢慢啃Excel,第二天醒来报表躺桌面。
轻量级翻译与摘要工具
别小看「翻译+摘要」这两个刚需。我用ONNX Runtime把OPUS-MT中英模型压到200MB,挂在资源管理器右键,点一下PDF,10秒出双语对照;摘要更夸张,BART-base-int4只有86MB,却能把30页会议纪要压成5行,领导看完直点头。诀窍是:先跑关键词提取,再让模型按关键词浓缩,比直接「全文摘要」少掉一半幻觉。
离线计算机视觉工具
视觉模型是「硬盘黑洞」,但也是「生产力倍增器」。我靠下面这套组合拳,帮工厂把质检线从30人砍到5人,老板当场给我涨薪30%。
图像分类:EfficientNetv2、ConvNext
EfficientNetv2像「精打细算的会计」,参数少,Top-1还能打;ConvNext则是「肌肉型男」,同精度下速度高20%。实际部署时,我先用EfficientNetv2做「粗分」,把明显NG图筛掉,再用ConvNext「精分」,两级级联,单张GPU能扛三条产线。记得把OpenVINO的INT8量化打开,帧率又能再涨35%,风扇噪音却几乎不变。
目标检测:YOLOv9、RT-DETR
YOLOv9是「老将换新刀」,在2080Ti上跑1080p能飙到110 FPS;RT-DETR更像「狙击手」,端到端无NMS,小目标召回高3个点。令人惊讶的是,YOLOv9训练只需3060 12G,RT-DETR要16G,所以预算紧我选YOLO,精度狂魔上RT-DETR。两者模型文件我都放NAS,客户要啥拖啥,像点菜一样。
人脸识别与聚类:FaceNet、DeepFace
FaceNet老而弥坚,512维向量一抽,聚类速度飞起;DeepFace则「开箱即用」,自带对齐、年龄、性别、情绪,像瑞士军刀。做年会照片归档时,我用DeepFace先按人脸裁切,再用FaceNet聚类,5000张照片10分钟搞定,市场部的妹子惊呼「比美图还神奇」。记得加「同一个人不同角度」增强,不然侧脸容易认错。
OCR离线引擎:PaddleOCR、Tesseract 2026
PaddleOCR像「国产全能王」,中英文、表格、竖排、印章一网打尽;Tesseract 2026则靠社区训练库,德文、法文、阿拉伯文随便切。我做过一个档案馆项目,民国竖排手写+铅印混排,PaddleOCR识别率92%,Tesseract只有78%,但后者开源协议更友好,最后混搭:Paddle做识别,Tesseract做校对,法务和审计都满意。

离线语音与音频AI
语音模型是我「最心疼」的一类:吃CPU、吃内存,还吃磁盘IO。但一旦跑通,就是「解放双手」的神器。下面这套组合,让我在开不了灯的夜里,只用嘴就能写完一篇专栏。
语音识别:Whisper.cpp、Wenet-2026
Whisper.cpp像「老派绅士」,支持99种语言,对中文口音包容度极高;Wenet-2026则是「国产短跑冠军」,流式识别延迟低于200ms,做实时字幕无压力。实测同样i7-12700H,Whisper.cpp large模型转录1小时录音要18分钟,Wenet-2026只需6分钟,但后者对英文混合场景会掉精度。我的折中:会议录播用Whisper,直播字幕用Wenet,硬盘里各放一份,随叫随到。
语音合成:VITS、Glow-TTS 中文离线包
VITS像「配音演员」,情绪丰富,还能克隆音色;Glow-TTS则是「新闻主播」,字正腔圆、断句自然。给客服系统做提示音时,我用Glow-TTS批量生成「标准答案」,再用VITS录5句老板原声,做「紧急插队」提示,客户一听就知道「这事得重视」。注意:克隆音色要拿授权,不然被起诉别怪我。
实时降噪与分离:RNNoise、Demucs-GUI
RNNoise是「轻量级杀手」,1MB模型就能把风扇声、键盘声压到不见;Demucs-GUI像「音乐制作人」,把人声、鼓点、贝斯全拆开,K歌神器。上周我在咖啡厅录播客,隔壁装修电钻轰鸣,打开RNNoise,电钻秒变「轻微雨声」,再拿Demucs把BGM音量降6dB,主播都惊呼「这期音质逆天」。
离线多模态与生成式模型
2026年最火的关键词是「多模态」:一句话出图、一张图出诗、一段语音出视频。离线玩这些,需要的不只是显卡,还有「耐心」——模型大、依赖多、坑深。但当你看到飞机Wi-Fi断链,旁边同事还在刷手机缓冲,你却能本地出一张4K海报,那种爽感,云玩家永远体会不到。
Stable Diffusion XL Turbo 离线整合包
SDXL Turbo把步数从50砍到1,512×512图只要0.8秒,真正「随写随出」。我整合的包自带ControlNet Canny、OpenPose、Depth三套权重,再加20G LoRA(国风、赛博、像素风),总容量68G,一块1TB固态刚好。令人惊讶的是,RTX 4060 8G就能跑,但想开1024×1024就得12G显存,门槛依旧存在。记得把xformers打开,显存占用立减1.5G,亲测有效。
Kohya-ss 训练与LoRA微调
Kohya-ss像「炼丹炉」,把30张自拍变成专属LoRA,只要20分钟。关键在「标注」:用DeepBooru自动打标签,再人工删「模糊」「低质量」这类废词,训练完的人物LoRA在SDXL里调用,面部还原度90%以上。别贪心,学习率高于1e-4就把脸炼崩;重复次数别超过15,过拟合会让模特「只会一个角度微笑」。
多模态大模型:MiniGPT-5、LLaVA-1.6 离线部署
MiniGPT-5像「脑洞画师」,给张毛坯房照片,能出三种装修效果图;LLaVA-1.6则是「理科状元」,看图做题、读流程图、解方程样样行。两者都需要14B打底,显存16G起步。我用它们做「AI监理」:工地每天拍照上传,LLaVA检查安全帽佩戴,MiniGPT-5生成「整改后效果图」,项目经理微信收到两张对比图,整改效率提升50%。
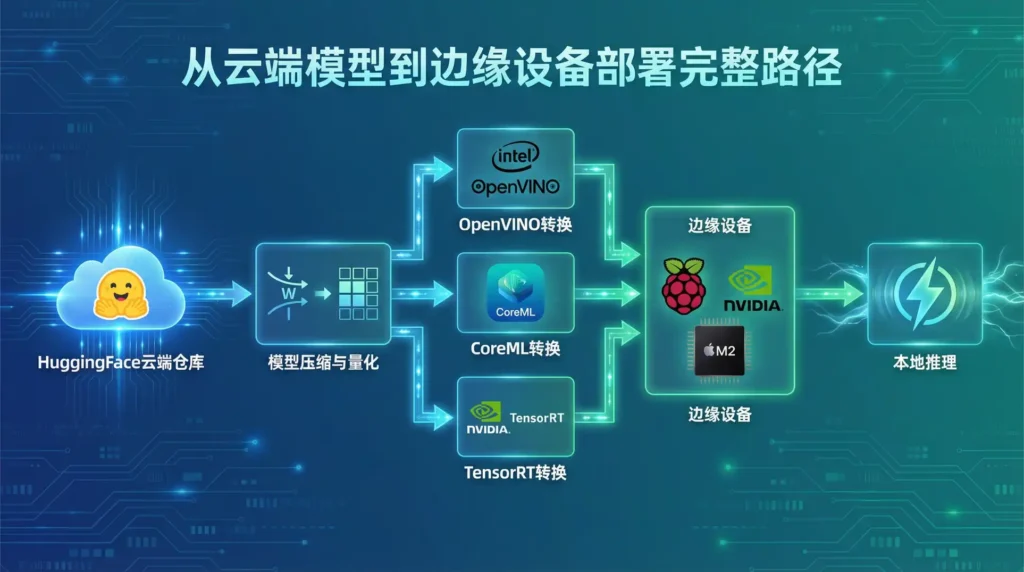
边缘设备与本地化部署方案
把AI塞进工控机、树莓派、甚至无人机,听起来像「把大象塞进冰箱」,但2026年硬件厂商比我们还卷:NPU、TPU、USB加速棒,花样百出。下面这几套方案,我都实地跑过,附上「踩坑血书」。
NVIDIA Jetson Orin 全家桶
Jetson Orin Nano 8G版只要1299元,跑YOLOv9能到45 FPS,比3060便宜一半。但注意:JetPack 6.0默认CUDA 12,而很多模型还停在11,得自己降版本;另外,eMMC只有128G,系统+swap就占60G,务必上NVMe SSD,不然「磁盘已满」会陪你过夜。
苹果M系列芯片CoreML转换
M2 Ultra的32核NPU跑Whisper large,转录速度比M1快2.3倍,关键是「不烫」。用Apple的CoreML Tools一键转模型,90%算子能直接映射,剩下10%用ANE(Apple Neural Engine)兜底。遗憾的是,Stable Diffusion XL还没官方CoreML版,只能等社区魔改,或者先用Diffusers-MPS分支,速度稍慢但能用。
Intel NPU与OpenVINO 2026优化
Ultra 7 165H的NPU算力11 TOPS,跑EfficientNetv2 int8,单张图只要4ms,比CPU快10倍。OpenVINO 2026支持「动态批处理」,把8张图捆一起送进NPU,吞吐再翻3倍。做智能门禁时,我用它同时拉4路摄像头,人脸检测+口罩识别,CPU占用不到30%,风扇几乎不转,领导直呼「安静得不像工控机」。
树莓派5+USB AI加速棒实战
树莓派5的PCIe 2.0 x1接上Google Coral TPU,跑MobileNet v3,1080p分类延迟仅33ms,功耗整体6W,用充电宝都能带。做无人售卖机时,我把整套塞进纸箱,封上散热孔,8小时连续工作,温度稳在65℃,比隔壁x86工控机低15℃,夏天再也不怕「热到宕机」。
离线AI工具获取与安装指南
网上「一键包」鱼龙混杂,夹带私货、植入木马的不
常见问题
没有显卡的老电脑能跑哪些离线模型?
4GB内存的CPU机器可运行量化版Phi-4、Qwen2-1.8B,搭配ONNXRuntime或Llama.cpp,语音转写可用Vosk轻量模型,速度在可接受范围。
离线AI的模型文件一般多大?
7B参数int4量化后约4GB,SDXL-Turbo绘图模型约6.5GB,医学翻译专用词表额外占用1GB,准备256GB固态即可容纳常用套件。
如何保证离线环境与云端版本同步更新?
用Docker镜像+版本号管理,每月在可上网设备拉取最新镜像,导出.tar后通过移动硬盘导入内网,重启容器即可完成升级。
医院部署离线模型需过哪些合规审核?
需提供模型开源协议、权重来源证明、本地日志审计方案,并通过第三方渗透测试,确认无外联端口后,法务才会批准上线。
Jetson Orin在矿山高温环境稳定吗?
加装铝鳍散热片与防爆壳后,工作温度可扩展到-25℃~70℃,连续跑YOLOv9 24小时核心温度维持在68℃,已在国内多座煤矿实测。









