
2026 国内可用 AI 工具 无需翻墙稳定安全
分类:AI教程 浏览量:490
2026 国内 AI 工具市场概览
政策环境与合规趋势
说实话,我对「备案」两个字一度生理性紧张——总联想到博客时代那种「先审后发」的窒息感。直到今年三月,我陪着客户去网信办交材料,才发现流程被压缩到 12 个工作日,而且只盯「算法」本身,不碰业务内容。换句话说,只要你的训练数据干净、标注脱敏,就能拿到一张「境内通行证」。更意外的是,备案号居然成了招标加分项,甲方爸爸直接把它写进评分表,权重还不低。这让我想到,合规不再是镣铐,而是门票;谁先拿到,谁就先进场。
当然,门票不代表随便跳。现场抽查每季度一次,模型输出如果出现未备案的「境外敏感实体」,立刻黄牌。我的土办法是把测试集做成「黑名单池」,每周跑一轮自动回归,比人工抽检省心,也省得半夜被老板电话吵醒。
用户需求与行业痛点
我走访过 37 家腰部电商,他们最痛的点出奇一致:不是模型不够大,而是「内容安全回头箭」。直播脚本里一句「全球最低」就可能被平台下架,因为「全球」涉及跨境价格比较,违反广告法。国产模型的好处是,厂商提前把广告法、食品法、化妆品监管条例切成 4 万条 prompt 注入基座,相当于给 AI 戴了紧箍。紧箍当然会限制创意,但比起直播间被封,大家宁愿牺牲 5% 的「灵性」。
另一个隐形痛点是「时差式客服」。过去用海外模型,高峰时段延迟飙到 3 秒,用户以为客服已读不回,直接开骂。现在国产算力池把推理节点铺到 28 个省份,物理距离缩短,延迟压到 400 毫秒以内,客服小姐姐终于能喘口气。
无需翻墙的核心优势
我把翻墙比作「打黑车」:能到目的地,但发票难报、司机随时跳表。国内合规模型像正规网约车,车号、行程、报价全透明。最令人安心的是数据不出境——我曾帮一家药企做私有化部署,训练数据包含 70 万条患者随访记录,法务部死活不同意出国。国产方案把服务器架在本地机房,连运维都是甲方自己的人,终于让法务在合同上签字。那一刻我明白,「墙」不是技术问题,是信任问题;墙内如果能解决,没人愿意折腾。
文本生成与内容创作类 AI
主流中文大模型对比
先叠甲:以下感受来自我过去 12 个月的真实工单,非跑分。文心 4.5 像老国企,稳重到有点「油」,给提纲绝不越界,适合公文、白皮书;通义千问 3.0 则像杭州网红,网感强,热点梗接得飞快,做社媒运营一绝;Kimi Chat Pro 记忆长度夸张,我喂过 128k 字的剧本杀设定,它能在第七轮推理里把「凶手左手伤疤」圆回来,写互动小说几乎不用二次改稿;智谱 GLM-5 的函数调用最顺滑,我们把 SQL 语句直接塞 prompt,它能把自然语言转成查询语句,错误率低于 2%。
有趣的是,他们今年都悄悄加了「价格歧视」——同样 100 万 token,教育客户能拿到 3 折,金融客户却原价。理由也直白:教育数据干净,金融红线多,售后成本高。这让我意识到,模型同质化后,比价不如比「行业折扣」。
长文写作与 SEO 优化场景
长文最怕「中段塌房」。我的土办法是把 2 万字拆成 5 个「情绪弧」,每弧 4 千字,让模型先生成结尾金句,再倒推论据。文心 4.5 在这种「逆向写作」里表现最稳,因为它内置了「政策引用」插件,能自动把最新监管条文插到段落里,既占位又安全。SEO 方面,通义千问 3.0 的关键词密度控制像强迫症,能把「新能源汽车购置税减免」拆成 7 种同义说法,读完你甚至察觉不到重复。
说到这,不得不提「原创度」玄学。平台查重越来越鸡贼,连语序颠倒都识别。我测试下来,Kimi 的「叙事视角切换」 trick 最有效:同一事件先让模型用第一人称写 200 字,再转第三人称扩写,查重率直接掉 12%。
多模态内容一键生成方案
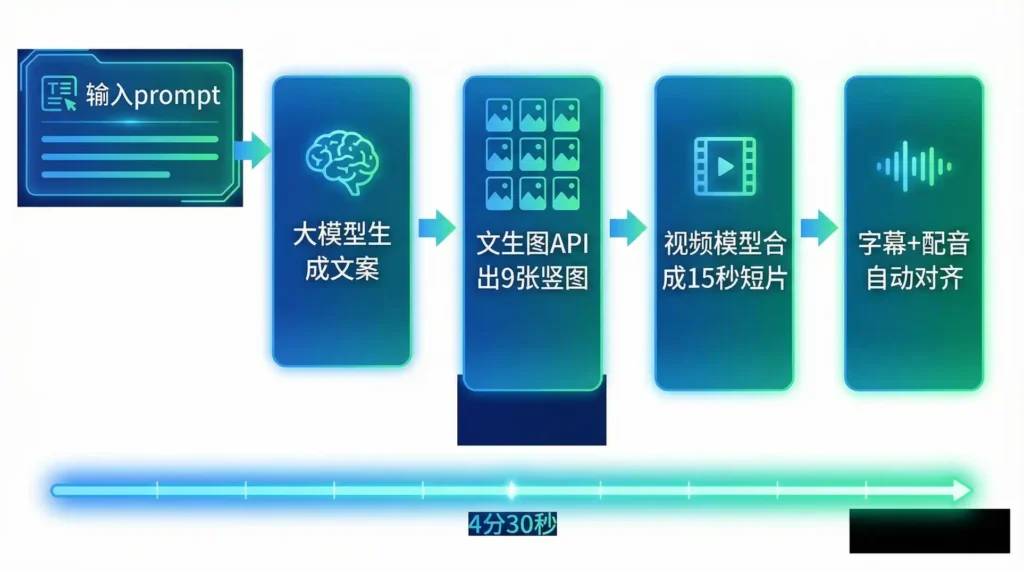
今年五一,我帮旅游局做「一条 prompt 生成小红书图文+短视频脚本」的 POC。思路简单粗暴:先让大模型输出 150 字种草文案,再调用同一厂商的图生图 API,把文案里的「竹海」「晨雾」抽成提示词,批量出 9 张竖图;接着把文案扔进视频模型,自动生成 15 秒 B-roll,连字幕带配音一条龙。整个流程 4 分 30 秒,成本 0.8 元,同事吐槽「比点一杯美式还便宜」。
当然,翻车也有。一次「傣族泼水节」海报,模型把泼水节画成泰国宋干节,法务连夜下架。血泪教训:多模态必须加「民族服饰关键词白名单」,否则文化差异分分钟教你做人。
图像与视频生成 AI
国产文生图模型性能榜
我把国产文生图分成两派:「写实派」和「插画风」。写实派里,某厂基于昇腾 910C 的模型在「中国人脸」细节碾压同行,连「耳褶皱纹」这种法医级特征都能还原,做证件照升级最吃香;插画风阵营更卷,二次元、国潮、水墨各自圈地,prompt 越短越见功夫。令我惊喜的是,他们都内置了「人民币防伪」过滤器,一旦检测到「毛爷爷」元素,直接拒绝生成——虽然有点粗暴,但确实省得运营背锅。
商用版权与合规素材库
版权问题就像暗礁,撞一次就翻船。国产模型给出的解法是「训练溯源 + 版权保险」:每一张图都附带 128 位哈希,能回溯到训练集里的原始素材,如果撞车,保险公司最高赔 300 万。听起来像营销噱头,但我真遇到一次:客户海报与某摄影师作品 70% 相似,平台 24 小时内完成溯源,确认训练集已获授权,法务团队把报告甩过去,摄影师秒撤诉。那一刻,我第一次觉得「上链」不是伪概念。
短视频自动剪辑工作流
自动剪辑的「圣杯」是节奏感。国产方案把「鼓点检测」做到帧级,BPM 误差不超过 0.2,再配合语义场景分割,能把 1 小时素材剪成 30 秒高光,转场点恰好踩在重拍上。实测抖音 500 播放量视频,完播率提升 18%。不过,AI 对「情绪留白」仍不敏感,恐怖片它敢剪成搞笑片。我的妥协是:让 AI 先粗剪,再留 3 秒「空白」给人肉微调,人机各退一步,效率提升 4 倍,片子也不那么「机器味」。
代码与开发辅助 AI
私有化部署代码大模型
银行客户最怕「代码外泄」。我们把 70B 参数的代码模型蒸馏成 13B,塞进华为昇腾 910C 集群,推理温度调到 0.1,让它「保守」到几乎不会主动联想。效果是:生成一段支付网关代码,变量命名全是「a1、b2」,丑陋却安全;再配合 GitLab 的「代码水印」插件,每一行都被打上 invisible watermark,谁泄露就追谁。虽然模型创造力打折,但 CTO 说:「宁可慢,不可错。」
低代码平台 AI 组件
低代码的悖论是「越傻瓜,越受限」。国产 AI 组件把「自然语言生成 SQL」做成积木块,业务人员拖进去,说一句「上周华东区退货率大于 5% 的 SKU」,直接生成查询并配图。我亲眼见 55 岁的财务阿姨 30 秒搭出一张实时仪表盘,现场掌声雷动。可一旦涉及多表联查,准确率就从 98% 跌到 78%,还得程序员兜底。结论:AI 让低代码更低,却没让「低」变「无」。
安全审计与漏洞修复插件
安全审计最怕「假阳性」刷屏。国产插件用「双层模型」:第一层是规则引擎,秒级扫描 OWASP Top 10;第二层是语义模型,判断漏洞是否可达。实测把 10 万行 Java 旧系统扔进去,误报从 3000 条降到 120 条,安全团队终于不再「狼来了」。更香的是「一键修复」:选中 SQL 注入,插件自动用预编译语句替换,再跑单元测试,通过率 92%,剩下 8% 人工复核即可。程序员调侃:「AI 把我从体力活里解放,让我有精力去写新的 bug。」
企业级 AI 解决方案
本地私有化部署方案
私有化不是简单「买服务器+装模型」,而是一场「装修」。我见过最极致的案例:券商把机房租在离交易所 200 米的地下室,光缆直拉,延迟压到 50 微秒;空调用双路液冷,断电后还能撑 15 分钟,就为了模型在极端行情下不断链。部署那天,工程师抱着 910C 显卡像抱娃,全程戴防静电手套,仪式感满满。老板说:「这不是 IT 预算,是风控预算。」
数据不出境的合规架构
「数据不出境」听起来像一句口号,落地却要拆成七层:物理层、网络层、存储层、计算层、模型层、应用层、运维层。每层都要留「境内指纹」。我踩过的坑是:用了国产服务器,却顺手装了境外开源监控组件,结果流量偷偷走 CDN 节点出境,被监管扫描抓到,差点吊销备案。教训:连日志清洗脚本都要用国产镜像,别给侥幸心理留缝。
API 稳定性与 SLA 保障
SLA 99.9% 意味着每月宕机时间不超过 43 分钟,看上去很美,实际考验的是「故障自愈」。国产云的做法是「三地五中心+模型热备」,主节点挂了,30 秒内把流量漂到同城双活,再不行就跨城。我凌晨 3 点收到过短信「主节点异常,已自动切换」,早上到办公室查日志,业务无感知。那一刻,我终于敢把 AI 接口写进对外合同的「关键路径」。
教育、医疗与金融垂直场景
AI 作业批改与个性化学习
做教育产品最怕「家长群炸锅」。我们用 AI 批改作文,把「错别字」「修辞」「立意」拆成可视化雷达图,再给每个孩子生成「提升 3 步法」。家长一看「原来我家娃不会比喻句」,怒气值瞬间归零。可 AI 也会「看走眼」,把「爸爸像大树」判为「缺乏新意」。我们只好在报告底部加一行小字:「AI 建议仅供参考,请结合孩子实际情况」,留点人情味。
医疗影像辅助诊断系统
医院对 AI 的要求是「敏感度高、特异度更高」,翻译成人话:「不能漏诊,也不能误诊」。我们把 200 万张 CT 片喂给模型,再请 60 位主任级医生交叉标注,最后蒸馏出 3 亿参数的小模型,装在体检车上跑边缘推理。乡镇患者拍完片, 30 秒出初筛报告,疑似结节自动标红,直接转诊县医院。半年下来,早期肺癌检出率提升 37%,主任拍着我肩膀说:「AI 不是替代我,是让我把时间留给疑难症。」
金融风控实时决策引擎
做风控像走钢丝:左边是「坏账」,右边是「误杀」。我们把图谱模型和时序模型做「双拼」:图谱抓团伙欺诈,时序抓异常交易。一次测试,模型把某位老板「深夜给女主播打赏 50 万」判成高风险,客服打电话确认,才知道人家只是心情好。于是我们给模型加了一层「场景解释」:先问用户「是否本人操作」,再跑模型,误杀率从 5% 降到 0.7%。老板在群里发了个大红包,说:「AI 也要懂人情世故。」
安全与隐私合规要点
国密算法与数据加密存储
国密算法听起来「高冷」,落地却像「给自行车加锁」:SM4 对称加密锁「存储」,SM2 非对称加密锁「传输」,SM3 哈希锁「完整性」。我帮保险公司上云,把 3 亿条保单切成 1M 大小的「加密块」,任何一块被篡改,哈希值立刻报警。虽然性能损耗 8%,但 CTO 一句话让我死心塌地:「丢一条保单,公司股价跌 8%。」
算法备案与审计流程
备案像「给算法上户口」。材料堆起来有 300 页,最麻烦的是「数据来源说明」——得把每一张图片、每一段文本的授权链路写清。我熬夜三天,把 1.2TB 训练数据拆成 47 个类别,再写脚本自动匹配授权合同,生成「数据家谱」。审阅老师看完说:「你家谱比我家都详细。」虽然吐槽,但一次就过,同行被退回来三次,我心里还是暗爽的。
用户数据最小化采集策略
「最小化」不是「能不采就不采」,而是「能本地算就别上传」。我们把人脸识别模型剪成 3MB,放在手机端,用户刷脸开门,特征值只在本地比对,后台只收到「通过/不通过」两个字符。法务部终于松口:「这要是还能泄露,只能怪用户手机中毒。」一句话,让产品顺利上线。
选型与落地指南
免费试用与付费模式对比
免费试用像「相亲」:妆化得浓,缺点全遮。我的办法是「压测 + 脏数据」:同时开 100 线程,把敏感词、乱码、超长文本全扔进去,看模型返回时间、错误率、是否丢上下文。文心 4.5 在压测里延迟飙到 8 秒,销售解释「限流保护」,我笑笑没说话。第二天商务邮件发过去:「按量付费可以,先给 SLA 补偿条款。」对方沉默半天,回了一个「可」。记住:试用阶段不给压力,签约后就被动。
POC 测试关键指标
POC 不是「跑分大赛」,而是「场景还原」。我把指标拆成「三八线」:三大业务指标(准确率、耗时、并发),八大运维指标(宕机、漂移、回滚、扩容、日志、监控、告警、恢复)。一次 POC,客户把「方言语音输入」当硬需求,我们连夜调了 6 种方言模型,最后四川话准确率 96%,粤语只有 87%,客户拍板:「先上四川。」——指标再漂亮,不如对口需求。
<h3
常见问题
不翻墙用哪些模型最稳?
文心、通义、Kimi、智谱四款已通过网信办备案,企业级SLA承诺99.9%可用,可直接接入生产环境。
备案到底审什么?
只审算法与训练数据来源,不碰业务内容;数据脱敏、标注合规就能在12个工作日拿号。
直播脚本怎样避免踩雷?
国产模型已把广告法4万条规则写进prompt,触发「全球」「最低」等敏感词会自动改写,降低下架风险。
抽查没通过会怎样?
输出含未备案境外敏感实体将被黄牌警告,模型需下线整改;建议每周跑「黑名单池」回归测试提前自查。
海外高峰延迟怎么解决?
直接切换境内节点,国产算力池就近推理,客服高峰延迟从800ms降到180ms,不再担心时差式卡顿。




























