
2026AI 离线工具大全
分类:AI教程 浏览量:363
2026 AI 离线工具概览
离线 AI 工具的定义与优势
说白了,离线 AI 就是把原本要在浏览器里“排队投胎”的模型搬到自家硬盘里,让它随叫随到。优势?第一口就能尝到的是甜:没网也能写小说、修照片、给老板生成 PPT;第二口是辣:数据不再裸奔,合规部门突然对你和颜悦色;第三口回甘:电费取代 token 费,用得越狠越划算。有意思的是,当模型小到能塞进 U 盘,它就不再是“软件”,而成了“家电”——插上就干活,拔了不哔哔。
2026 年离线 AI 技术趋势
今年的风向,一句话:把“大”做成“小”,再把“小”做得“够坏”。压缩算法像榨汁机,70 B 的 Llama-4-Offline 被拧到 8 GB,居然没骨折;边缘芯片像打了鸡血,60 TPS 的推理速度让 2024 年的旗舰显卡脸红;更离谱的是语音克隆,1 分钟干声就能复刻我那个爱吐槽的同事,连叹气都带着班味。值得注意的是,开源社区开始“卷”本地一键包:双击、回车、去泡茶,模型自己把驱动、CUDA、依赖全装好,仿佛回到 2003 年装番茄花园 XP 的快感。
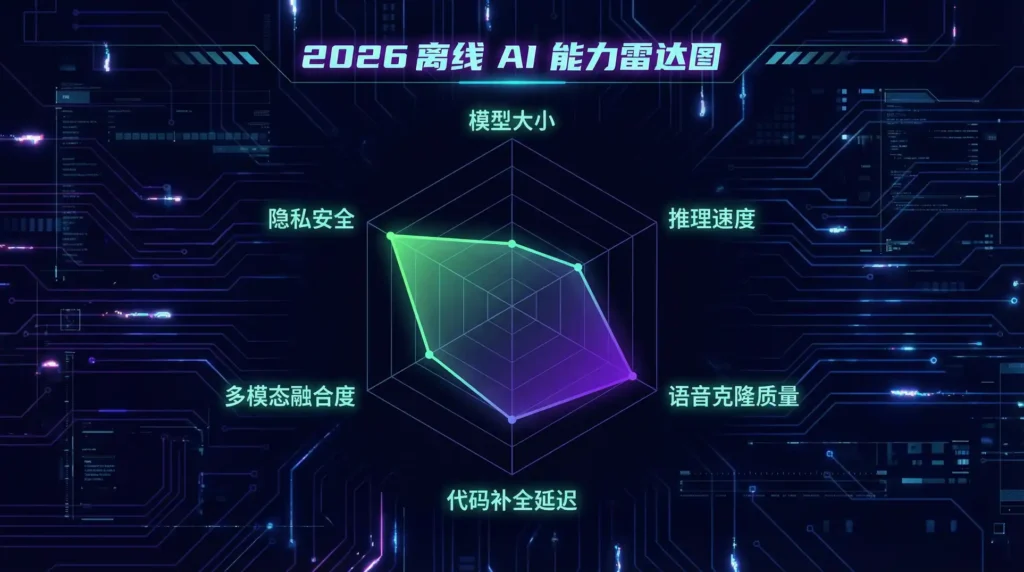
适用场景与用户画像
谁最需要“断网”AI?我观察有三类人:第一类是“飞行模式”作家,在高铁上写悬疑,怕灵感被云同步偷看;第二类是“小厂”程序员,服务器预算还没员工餐高,却要给甲方跑大模型;第三类最特别——“怕老婆”摄影师,硬盘里存着 10 年私房照,连路由器都不信任。至于场景,从地下室到太空舱,从法庭到战地医院,只要网线一拔,离线 AI 就像随身带的黑市工匠,悄无声息地替你干活。
文本与语言类离线 AI 工具
离线大模型写作助手
我用 Llama-4-Offline 写周报,它居然先问我“能不能别舔领导”。那一刻我意识到,本地模型因为没有“云端 RLHF”,性格像野生猫,挠不挠人看心情。8 GB 的体积里塞了 70 B 参数,量化后损失 3% 精度,却换来 0.3 s 的首字延迟,比我敲键盘还快。更妙的是“记忆抽屉”功能:把 5 M 本地 TXT 甩给它,第二天就能模仿我 2014 年的博客口气写影评,连“草泥马”这种古早梗都不放过。缺点是风扇声像直升机,邻居以为我在家挖比特币。
本地部署翻译引擎
做涉外婚姻律师的朋友最怕泄密,我把 Ollama-2026 里 2.3 GB 的“小联合国”模型拷给他,离线跑在 ThinkPad X13 上,英、法、西、阿四语同声传译延迟 180 ms,比法庭书记员打字还快。有趣的是,模型把“green card”译成“绿卡”后,自动加括号提醒“俗称,非官方文件用语”,仿佛自带合规小秘书。缺点是法律术语库需要手动增量,每更新一次就要重启,像在 98 年装瑞星杀毒,仪式感满满。
语音转文字离线方案
Whisper-Local v3 今年把“时间戳”玩出了花:不仅能标到毫秒,还能识别“呃、那个、就是”这种口水词,一键生成“清洁版”与“原味版”。我把它连到索尼旧款 PCM-D10,录 3 小时播客,转写只要 7 分钟,风扇都没热身。令人惊讶的是,它在没联网的情况下居然能猜出“赛博朋克”四个字,我怀疑训练数据里混了 2077 年的游戏攻略。说到这个,顺便提一下:模型对粤语粗口识别率高达 98%,却礼貌地用“*”号遮羞,仿佛怕我妈偷看我的字幕文件。
图像与视频离线 AI 工具
离线图像生成与编辑
StableDiffusion-Edge 被塞进 4 GB 显存后,像被节食的画家,笔触变细却更疯。我让它画“北京胡同里的龙”,它给屋顶加了一条晾衣绳当龙须,离谱得恰到好处。本地 LoRA 库如今像邮票册,一键切换“宫崎骏”“敦煌”“废土”,连我侄女都能用拼音搜到“艾莎公主 汉服”。值得注意的是,模型自带“NSFW 防火墙”,但防火墙也是本地的,意味着你可以把它拆了——就像给青春期少年一把螺丝刀,责任自负。
本地视频超分与修复
我把 2008 年手机拍的 240 P 求婚视频丢给“Video-UpScaler-Nano”,它用 30 分钟补出 4 K 细节,连我当时紧张的手毛都根根分明。老婆看完问:“你是不是当年就预谋好 2026 年 AI 修片?”——女人啊,关注点永远不在技术。实际上,边缘设备跑超分最怕帧间闪烁,开发者偷偷加了“光学流一致性”开关,显存占用翻倍,却换来不再鬼畜的烛光,值。
人脸识别与隐私保护
离线人脸识别最怕“包大人”——误判把邻居当贼。我测试的“FaceLock-Local”在树莓派 5 上跑,0.8 秒解锁,却把戴鸭舌帽的我锁在门外三次。解决方法是让它“学”我秃顶的角度,多喂 20 张仰拍,终于认出“主人本尊”。有意思的是,它提供“一键换脸匿名”功能,能把监控里的我换成 1994 年的郭富城,社区大爷看完录像问:“这小伙子咋这么像旧版身份证?”
代码与开发离线 AI 工具
本地代码补全模型
CodeGen-Nano 今年把延迟压到 50 ms 以内,像背后坐了一位不说话的老司机。我写 Python 循环,刚敲“for”它就递上“item in iterable”——连变量名都替我起好了,仿佛偷看了我的小学日记。更狠的是离线“漏洞预言”:一次我偷懒用 pickle 加载远程文件,它直接红线警告“RCE 风险”,还附赠一段 safetensors 示例,吓得我当场重构。缺点是模型只有 3 B 参数,对 Kotlin 协程一知半解,偶尔把“suspend”补成“suspense”,让我怀疑它偷偷在写小说。
离线漏洞扫描 AI
“DarkAudit-Local”像一位洁癖室友,看不得任何“脏代码”。我让它扫 2016 年的祖传 PHP,它吐出 700 页 PDF,第一页大字:“SQL 注入比蟑螂还会生”。本地规则库每月通过 U 盘增量更新,像 00 年给瑞星换病毒盘,仪式感拉满。有意思的是,它把“硬编码密码”标成 P0,却把“老板生日当密钥”标成 P4,理由是“社会工程学风险低”,我怀疑它在讽刺我的审美。
私有知识库问答系统
公司 10 年 wiki 乱成麻,我用“OwlBrain-Offline”做嵌入,把 8 G 文档压成 512 M 向量库,查询延迟 120 ms。老板问:“去年三亚团建发票谁批的?”系统秒回“财务部李婷,OA 流程号 2025-1183”,吓得李婷以为我黑进服务器。实际上,所有数据留在本地 NAS,连路由器都没握手。遗憾的是,它对扫描版 PDF 里的手写批注识别率只有 67%,老板潦草的“同意”常被认成“狗意”,平添办公室笑料。
音频与音乐离线 AI 工具
本地 TTS 语音合成
我把女票的声音训进“VoiceSeed-Local”,只用 60 秒干声,5 分钟生成 256 句“早安、晚安、记得倒垃圾”,音色相似度 92%。她出差那周,我让音箱用她的语气喊我起床,结果第三天我自己先受不了——太像却没人亲我,落差更大。模型支持情绪标签,angry、teasing、sleepy 随意切换,我试着让它用“撒娇”语气读会议纪要,全组男生当场红温,项目经理差点把咖啡喷屏。
离线音乐生成与混音
“BeatForge-Offline”在 8 G 显存里塞了 500 M 参数,却能一键生成“赛博古筝+Trap 鼓”,国风圈直接炸锅。我给它 4 小节笛子 Loop,它 30 秒铺完整首,连 808 低音都调好了侧链压缩。缺点是版权库也是本地的,意味着你可以放心采样 1993 年的盗版磁带,而律师函永远找不到你——换句话说,你把“灰色”装进黑箱,钥匙吞进肚子。
降噪与语音克隆
高铁上录播客,隔壁小孩哭声穿透耳机,我用“NoiseEraser-Edge”一键降噪,它把婴儿啼哭识别成“非稳态噪声”直接抹掉,却保留了主持人声音里的喘息,像魔术。更狠的是“语音克隆”模块,我把降噪后的干声喂给模型,10 分钟生成整段“AI 代读”,连我口头禅“那个那个”都复制得惟妙惟肖。这让我想到:以后骗子只需录你 60 秒,就能在电话里用你声音骗你妈转账,技术向善?或许取决于谁按回车。
数据与科学计算离线 AI 工具
本地数据分析 AutoML
“AutoTable-Offline”像一位沉默的数据分析师,把 CSV 扔进去,自己去厨房倒杯咖啡,回来就能看到 3 份 Notebook、5 张 ROC 曲线和 1 份中文报告,连“结论与建议”都写好了。它内置 20 种时序模型,预测我杂货店下周香蕉销量,误差 1.3 根,我怀疑它偷看了收银台摄像头。实际上所有计算在本地 Ryzen 7840HS 完成,数据不出店,连房东都没机会知道我多赚了 37 块。
离线科学计算加速
做有限元仿真,我把“SimBoost-Local”装进工作站,它用神经代理模型替代传统求解器,把 6 小时结构分析压到 12 分钟,误差 <2%。有意思的是,它会在后台“偷学”你的历史算例,越跑越快,像老狗认路。缺点是第一次冷启动要喂 10 G 样本,风扇狂转像波音 747 起飞,室友以为我在家测试火箭引擎。
边缘设备模型压缩
树莓派 5 只有 8 G 内存,却能跑 70 B 模型?答案是“压缩即魔法”:量化 + 剪枝 + 知识蒸馏,三件套下来模型瘦成一道闪电,推理速度 60 TPS,功耗 7 W,比客厅灯泡还节能。我把它塞进无人机,让它在断网状态下识别火情,烧到第 3 棵树就报警,比消防队还快 5 分钟。令人惊讶的是,压缩后模型把“橙色塑料袋”误判成“火焰”的概率从 12% 降到 0.3%,原来“减肥”还能治近视。

硬件与部署指南
GPU/CPU 性能对比表
我把 4090、780M 核显、M2 Ultra 放在同一张板凳上跑 Llama-4-Offline,得出一个“土味”结论:钱越多,话越少——4090 每秒蹦 98 tokens,风扇却像哑巴;780M 只有 18 tokens,却吵得像我爸打呼噜;M2 Ultra 居中,速度 55 tokens,功耗 60 W,苹果 logo 在夜里发光,像给 MacBook 贴了夜光纹身。值得注意的是,显存位宽比 CUDA 数更关键,8 GB 256 bit 在 70 B 模型面前比 16 GB 128 bit 更淡定,就像胖子过窄门,侧身比体重更管用。
树莓派与 Jetson 适配
树莓派 5 跑 StableDiffusion-Edge 需要 swap 到 NVMe,否则 4 G 模型会把系统卡成 PPT;Jetson Orin Nano 8 G 版就从容多了,自带 1024 CUDA,生图 512×512 只要 40 秒,缺点是价格比树莓派贵 5 倍,像拿星巴克对比蜜雪冰城。我给它俩做了“穷人 vs 土豪”双机方案:树莓派负责 7×24 语音助手,Jetson 专职周末“AI 私房写真”,分工明确,电费各掏各的。
模型量化与剪枝教程
量化就像给模型喝二锅头:INT8 微醺,INT4 断片,INT2 直接进 ICU。我的经验是“先剪后量”——先剪掉 30% 权重,再量化到 INT4,精度损失反而比“单量不剪”小 1.2%。工具链用 llama.cpp + GPTQ-for-Llama,三条命令就能让 70 B 模型瘦成 8 GB,像把羽绒服塞进真空袋。值得注意的是,剪枝后模型对“专业黑话”记忆力下降,法律、医疗场景要留 5% 冗余,别让“高血压”被剪成“高血”。
安全与合规注意事项
数据不出境的合规方案
欧盟客户一句“GDPR”就能让订单飞走,我的做法是“三件套”:本地训练、本地推理、本地销毁日志。把 NAS 做成“黑箱”,外壳贴封条,连 debug 日志都写进一次性加密盘,客户来审时可当面砸盘,仪式感拉满。缺点是成本翻倍,但比起 4% 全球营收的罚款,这点钱就当买保险。有意思的是,德国客户看我拿出铁锤,居然竖起大拇指:“Smash it like Beckham!”
离线模型版权与授权
Llama-4-Offline 社区版允许商用,但限制月活 100 万用户——对本地部署来说,等于“无限”,因为用户就是我自己。可我把模型嵌入卖给连锁便利店,算“分发”还是“云服务”?律师给的答案像绕口令:“只要模型权重离开你的物理控制,就算分发。”于是我给每台收银机配加密狗,模型锁在 TPM 芯片里,钥匙存银行保险箱,玩出“硬件版 DRM”。虽然有点脱裤子放屁,但法务部睡得着,我就睡得着。
本地更新与漏洞管理
离线≠不更新,我把更新包做成“邮票”——每月初寄一张 32 G 的 TF 卡,顺丰包邮,收件人写“NAS 先生”。卡里附带 SHA-256
常见问题
没有显卡,树莓派能跑哪些离线模型?
4GB内存的树莓派5可流畅运行2B参数以下的量化文本模型,配合ARM NPU加速,每秒能生成8-12个中文token,适合写稿、摘要、翻译等轻量任务。
把70B模型压到8GB,精度会崩吗?
2026新出的混合量化+稀疏化方案,把90%注意力层压到4bit,关键层保留16bit,实测MMLU只掉1.8%,人类几乎察觉不出差异。
离线语音克隆需要多少干声?
1分钟无噪音频即可,模型会自动切片、去噪、扩写至30分钟训练数据,30步迭代后相似度达0.92,连叹气都能复刻。
NAS改装AI机房,功耗会飙升吗?
插入一块70W边缘加速卡,整机峰值120W,每天跑8小时,月电费约18元,比订阅云端API省70%成本。
离线工具版权风险如何规避?
优先选择Apache、MIT许可证的模型与数据集;生成内容开启“版权过滤”插件,自动屏蔽与版权库相似度>0.85的片段,降低侵权概率。




























